Over-constrained prompts
Rules get added after every bad output until the model has no clear priority structure.

Prompt reliability workbench for AI automation teams
PromptProof audits messy system prompts, finds prompt debt, compiles cleaner versions, and proves improvements with eval-style reports.
Demo mode uses sample audit data. Built for agencies and teams that need defensible prompt changes before clients or users find regressions.
Sample audit fixture
Messy prompt
37 rulesYou are a sales research agent. Be concise but very detailed.
Return only JSON, but explain your reasoning clearly.
Never ask questions. Ask when information is missing.
Avoid generic language. Be specific. Do not be vague.
Diagnosis
Prompt Debt Score
72 -> 31
Conflicts Found
4
Redundant Constraints
9
Eval Pass Rate
61% -> 78%
Optimized + Eval Proof
# Output Contract
Return JSON with fit_score, signals, risks, outreach_angle, and rationale.
The problem
Most production prompts do not fail because they are too short. They fail because they collect prompt debt: duplicated rules, vague constraints, hidden conflicts, and instructions nobody can test.
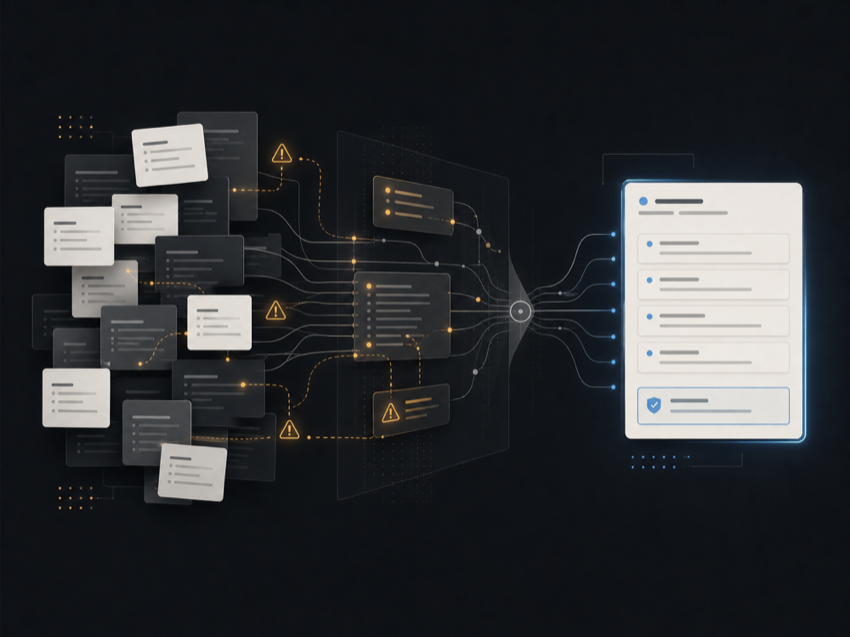
Rules get added after every bad output until the model has no clear priority structure.
"Be concise" and "explain everything in detail" live in the same prompt and nobody notices.
Version B feels better in one demo, but breaks three edge cases you forgot to test.
Clients ask whether the new prompt is better. You only have vibes.
How it works
PromptProof treats prompt improvement like a compiler pipeline: decompose the input, resolve the contract, run cases, and export the proof.
1. Diagnose
Split your prompt into atomic instructions and classify what each rule is supposed to prevent.
2. Compile
Merge redundant constraints, resolve conflicts, and rewrite vague instructions into a cleaner prompt structure.
3. Evaluate
Generate realistic test cases and compare original vs optimized outputs.
4. Prove
Export a report with scores, regressions, diffs, and the final optimized prompt.
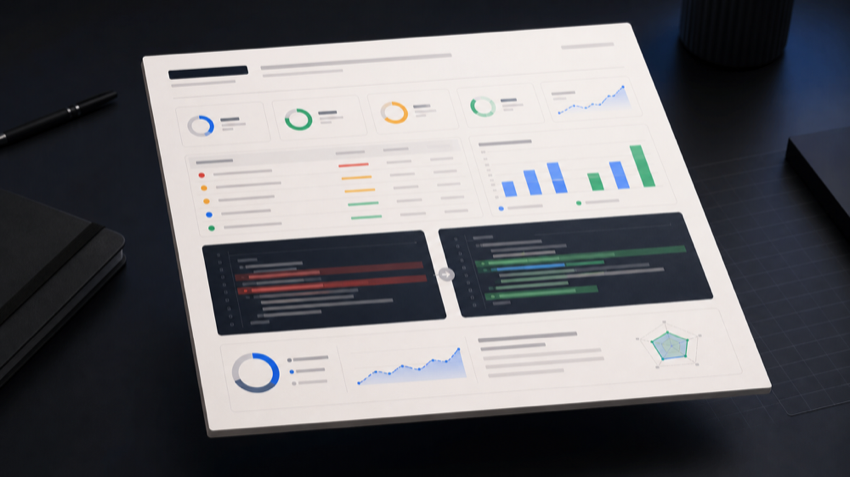
Product preview
PromptProof does not just rewrite text. It explains what changed, why it changed, and whether the result held up in tests.
Sample audit only. The preview uses fixed demo data and makes no backend request.
Use cases
The first version focuses on long prompts that sit inside client work, internal automation, extraction, support, RAG, and agentic workflows.
Audit client-facing prompts before they break in production.
Reduce generic outreach, hallucinated claims, and inconsistent formatting.
Test policy adherence, escalation behavior, and uncertainty handling.
Catch schema failures, missing fields, and fragile JSON instructions.
Clean up long system prompts and tool policies without losing intent.
Detect vague citation rules, hallucination risk, and missing fallback behavior.
Metrics
The report makes prompt quality visible through concrete debt, density, testability, regression, and before/after metrics.
Prompt Debt Score
How much clutter, conflict, and low-utility instruction load your prompt carries.
Decision Density
How much of the prompt actually helps the model make better decisions.
Constraint Testability
How many rules can be checked instead of merely hoped for.
Regression Rate
How often the optimized prompt loses against the original.
Before/After Delta
The measurable performance difference between two prompt versions.
Differentiation
A generator can rewrite your prompt. PromptProof keeps the original, diagnoses its failure modes, and shows the cost of the rewrite.
Pricing
Simple MVP plan previews for audit volume, eval depth, and report export. Billing is disabled on this demo.
Start with a prompt debt audit and a small eval set.
$0
For builders shipping repeatable client or internal workflows.
$49/mo
For small teams and agencies that need client-ready reports.
$199/mo
Plan limits are a preview for the MVP demo. Checkout and billing are not live yet.
FAQ
PromptProof reports scoped results instead of pretending one rewrite is universally better.
No. A generator gives you a new prompt. PromptProof diagnoses the old one, explains what changed, creates eval cases, and compares both versions.
Final check
Preview the audit flow with sample data, then connect the backend later for real prompt analysis.